The goal of the lab is to practice using a variety of raster geoprocessing tools to create models for sand mine suitably, and environmental and cultural risk within Trempealeau County in Wisconsin. During the lab I built a sand mine suitability model, and sand mine risk model, which I then followed by overlaying the two results to find the most suitable areas to sand mine characterized by the least amount of environmental and community impact.
Methods
Sand Mine Suitability Model
The first model was created to design an output for sand mine suitability based on the following criteria:
1) Geology
2) NLCD Land cover
3) Railroad terminals
4) Slope
5) Water table data
Each off these data sets were clipped to fit my study area of Trempealeau County, to determine a mining suitability rank for the land that falls inside this boundary. All of these feature layers were clipped to my study area, converted to a raster based on the desired field type, then reclassified. While reclassify, the feature class data values were divided into three ranks, based on their suitably for mining. Data ranges were given a 3 for more suitable, 2 for moderately suitable, and 1 for least suitable. The data ranges I chose for each data layer are descripted below for each data source, and listed in Figure 1. This allowed me to use raster calculator at the end of the lab to determine areas that had the highest and lowest suitability (Fig. 6).
Geology
Beginning with the geology of Trempealeau County, areas labeled as Jordan were most desired, and reclassed as a three, leaving the other geology types as a one.
NLCD:
Next, data from the NLCD website was gathered for Trempealeau County. Two rasters were created during this process. One raster included land with suitable mining area, and one included areas that should excluded from mining.
Rail Terminals
Next, rail terminal distance was taken into account. Here, I created a feature class of rail terminals that were within my study area of Trempealeau County. After this feature class was created, I ran the Euclidean Distance tool to display the distance after from this rail terminal. I then reclassified this feature class, and designated the areas closer to the terminal as most suitable, and farthest away as least suitable.
Slope
Following this, I used a DEM of Trempealeau County run the slope tool. The output generated a percent slope of areas within my study area. Next, I reclassify this based on the percent slope grade, and labeled the lowest slope as most suitable for mining, and the highest slope as least suitable.
Water Table
Using the watertable arc data, I used the convert the topo to raster tool. This gave me an output with the water table elevation in each cell. I then reclassified this data base on the elevation, where higher elevation was considered more suitable for mining by making it easier to collect water for the mining process.
Final Suitability Map
This output was created by using raster calculate to add all the above 5 layers together. Because I based my reclassify ranks as 3 to be areas of most suitability, adding the rasters allowed me to indicate areas with the highest final output raster cell value would be areas of highest suitability. This final map is displayed in Figure 6.
 |
| Figure 1: The five data layers used in the suitability model along with the data ranges chosen for reclassification of suitability. Reclass ranks are 0-3, where 3 represents most suitable, 2 represents moderately suitable, and 1 represents least suitable, and 0 represents excluded area. |
 |
| Figure 2: Sand Mine Suitability model created in Model Builder. |
Sand Mine Risk Model:
The first model was created to design an output for sand mine suitability based on the following criteria:
1) Streams
2) Farmland
3) Zoning
4) Schools
5) Wetlands
Each off these data sets were clipped to fit my study area of Trempealeau County, to determine a mining risk of impact to the land that falls inside this boundary. All of these feature layers were clipped to my study area, converted to a raster based on the desired field type, then reclassified. While reclassify, the feature class data values were divided into three ranks, based on risk of impact from sand mining. Data ranges were given a 3 for least risk for impact, 2 for moderately risk for impact, and 1 for least risk for impact. The data ranges I chose for each layer are descripted below for each data source, and listed in Figure 3. This allowed me to use raster calculator at the end of the lab to determine areas that had the highest and lowest risk for impact (Fig. 7).
Streams
Using the DNR hydro flowline data, I collected stream based on their ecological significance using the steam count field. Higher numbers were associated with primary, perennial running streams, and therefore were selected to be of high importance for analysis. These were selected out of the feature class and created into a new feature class. After, I projected it to WGS 1984 UTM 15N and clipped it to my study area. From here I ran the feature to raster tool, and next ran the Euclidean distance tool on the feature class. This gave me a final output of distance of each pixel to the nearest stream. I then reclassified this output, based on locations closest to the stream to have higher risk.
Farmland
Using the prime farm land feature class, I ran the feature to raster tool. Next, I reclassified the data based what time of farmland was more and least at risk. I specified areas such as agriculture fields and prime farmland should be of highest concern for impact, and areas not used as farmland should be considered of least concern.
Zoning
The zoning feature class was used to designate areas of highest potential for community impact. Within this class areas such as industrial, commercial, and residential zones were selected has areas to be avoided. Once these were created into a new feature class, I used feature to raster to convert it to a raster, followed by running the Euclidean Distance tool. This output gave me distance away from the areas, which I then reclassified, as areas closer to residential areas are of higher risk.
Schools
Here, I used the selected out the different schools within Trempealeau County to make a new feature class. After clipping and projecting the feature class to WGS 1984 UTM 15N, I was able to run the feature to raster to convert it to a raster, followed by running the Euclidean Distance tool. This output gave me distance away from the schools, which I then reclassified. Areas under 640 meters away from the school were considered excluded areas, and areas closer to the schools to be of higher risk
Wetlands
Here, I used the DNR wetlands feature class. After clipping and projecting the feature class to WGS 1984 UTM 15N, ran the feature to raster to convert it to a raster. Following this I ran the Euclidean Distance tool. This output gave me distance away from the wetland, which I then reclassified. I choose to specify areas under 800 meters (0.5 miles) away from the wetland were considered excluded areas, and areas as areas closer to the wetlands to be of higher risk.
Final Risk of Impact Map
This output was created by using raster calculate to add all the above 5 layers together. Because I based my reclassify ranks as 1 to be areas of highest risk, adding the rasters allowed me to indicate areas with the lowest final output raster cell value would be areas of highest risk of impact. This final map is displayed in Figure 7.
 |
| Figure 3: The five data layers used in the sand mining risk model along with the data ranges chosen for reclassification of suitability. Reclass ranks are 0-3, where 3 represents least at risk, 2 represents moderately at risk, and 1 represents most at risk, and 0 represents excluded area. |
 |
| Figure 4: First part of risk model created in Model Builder. |
 |
| Figure 5: Second part of risk model created in Model Builder. |
This was created by added the final outputs of the Suitability Model and Risk Model using raster calculator. Therefore, based on the ranking systems previously specified, areas of lowest risk and highest suitability would now have the highest values on the Final Sand Mine Suitability Map. This output was reclassified and displays areas on a scale of 1-3, where higher numbers are better suited for mining locations. This final map is displayed in Figure 8.
Results
 |
| Figure 6: Map of Final Sand Mine Suitability Map created by reclassifying the 6 data layers displayed on the left portion of the map, followed by added these raster layers together using raster calculator to get the final Suitability output. Reclass ranks are 0-3, where 3 represents most suitable, 2 represents moderately suitable, and 1 represents least suitable, and 0 represents excluded areas. Therefore, highest numbers on final output represent higher suitability for sand mining. |
 |
| Figure 7: Map of Final Sand Risk Map created by reclassifying the 5 data layers displayed on the left portion of the map, followed by added these raster layers together to using raster calculator get the final Suitability output. Reclass ranks are 0-3, where 3 represents least at risk, 2 represents moderately at risk, and 1 represents most at risk, and 0 represents excluded areas. Therefore, lowest numbers on final output represent higher risk of impact. |
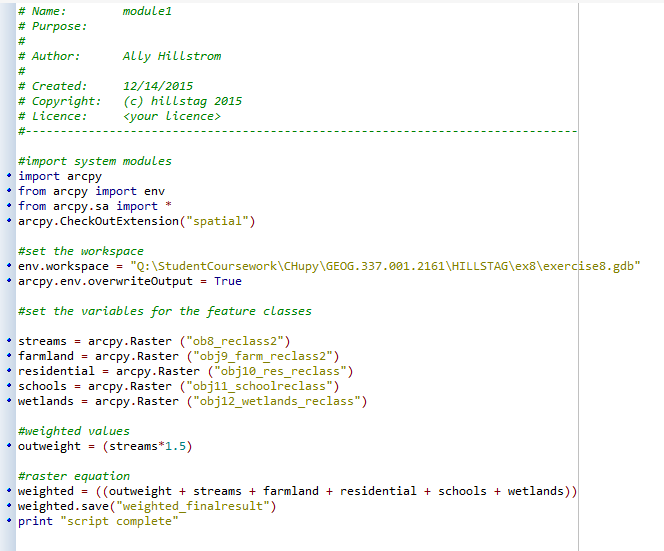 |
| Figure 8: Python Script ran to generate output picture in figure 9. Stream were used as a weighted factor, however residential, wetland, school, and farmland data were still included areas of assess risk. More details about script are listed in my PyScript blog tab. |
 |
| Figure 9: Python Output of Weighted Values. Python Script in figure 8, used to create this output. Stream were used as a weighted factor, however residential, wetland, school, and farmland data were still included areas of assess risk. |
Discussion of Results and Methods
My results show, that based on my criteria section and rank scheme that there are minimal suitable areas for sand mining in Wisconsin. This is not surprising knowing during reclassification, I typically gave increased protection to environmentally significant features, such as excluding all wetland areas as seen in Figure 7. Through this lab it was clear data organization is key to a creating credible model. Model builder was extremely help to organize the processes I had completed, and facilitated describing the process I took to find my results. Creating the ranking tables was also critical to keep track of what final outputs layers would be combined together at the final stage in raster calculator. Without these methods of organization, it would be easy to produce an erroneous final output. This is important to realize because these model can used to make important decisions that can have negative impacts on the surrounding areas. Additionally, this includes making sure to use reliable and updated data, and to update the model created frequently due to changes such as in infrastructure and community growth.
Conclusion
The process of generating a Raster Model requires attention to detail and the ability use spatial data and apply it to a real world phenomena. This activity require me to practice data and methods organization through using model builder and excel. This also required me to use a variety of tool independently but also in series to generate a final output. Lastly, in at the end of the project, I was able to combine my data output into a final model that provide information on the topic of sand mine suitability which allowed me to practice a real world GIS application.










